

Una base de datos vectorial es una colección de datos donde cada datos se almacena como un vector (numérico). Un vector representa un objeto o entidad, como una imagen, persona, lugar, etc. en el espacio n-dimensional abstracto.
Los vectores, como se explica en el capítulo anterior, son cruciales para identificar cómo están relacionadas las entidades y pueden usarse para encontrar su similitud semántica. Esto se puede aplicar de varias maneras para el SEO, como agrupar palabras clave o contenido similares (usando KNN).
En este artículo, vamos a aprender algunas formas de aplicar la IA al SEO, incluida la búsqueda de contenido semánticamente similar para la vinculación interna. Esto puede ayudarlo a refinar su estrategia de contenido en una era en la que los motores de búsqueda dependen cada vez más de LLM.
También puede leer un artículo anterior de esta serie sobre cómo encontrar canibalización de palabras clave utilizando los incrustaciones de texto de OpenAI.
Vamos a sumergirnos aquí para comenzar a construir la base de nuestra herramienta.
Comprensión de las bases de datos de vectores
Si tiene miles de artículos y desea encontrar la similitud semántica más cercana para su consulta objetivo, no puede crear integridades vectoriales para que todos ellos se comparen, ya que es muy ineficiente.
Para que eso suceda, necesitaríamos generar integridades vectoriales solo una vez y mantenerlos en una base de datos que podamos consultar y encontrar el artículo de coincidencia más cercano.
Y eso es lo que hacen las bases de datos vectoriales: son tipos especiales de bases de datos que almacenan incrustaciones (vectores).
Cuando consulta la base de datos, a diferencia de las bases de datos tradicionales, realizan vectores de coincidencia de similitud y retorno de coseno (en este caso, los artículos) más cercanos a otro vector (en este caso una frase de palabras clave) que se consulta.
Así es como se ve:
En la base de datos de Vector, puede ver vectores junto con metadatos almacenados, que podemos consultar fácilmente utilizando un lenguaje de programación de nuestra elección.
En este artículo, utilizaremos Pinecone debido a su facilidad de comprensión y simplicidad de uso, pero hay otros proveedores como Chroma, BigQuery o Qdrant que desee consultar.
Vamos a sumergirnos.
1. Cree una base de datos vectorial
Primero, registre una cuenta en Pinecone y cree un índice con una configuración de “Texto-Embeding-ADA-002” con ‘Cosine’ como una métrica para medir la distancia del vector. Puede nombrar el índice cualquier cosa, lo nombraremosarticle-index-all-ada‘.
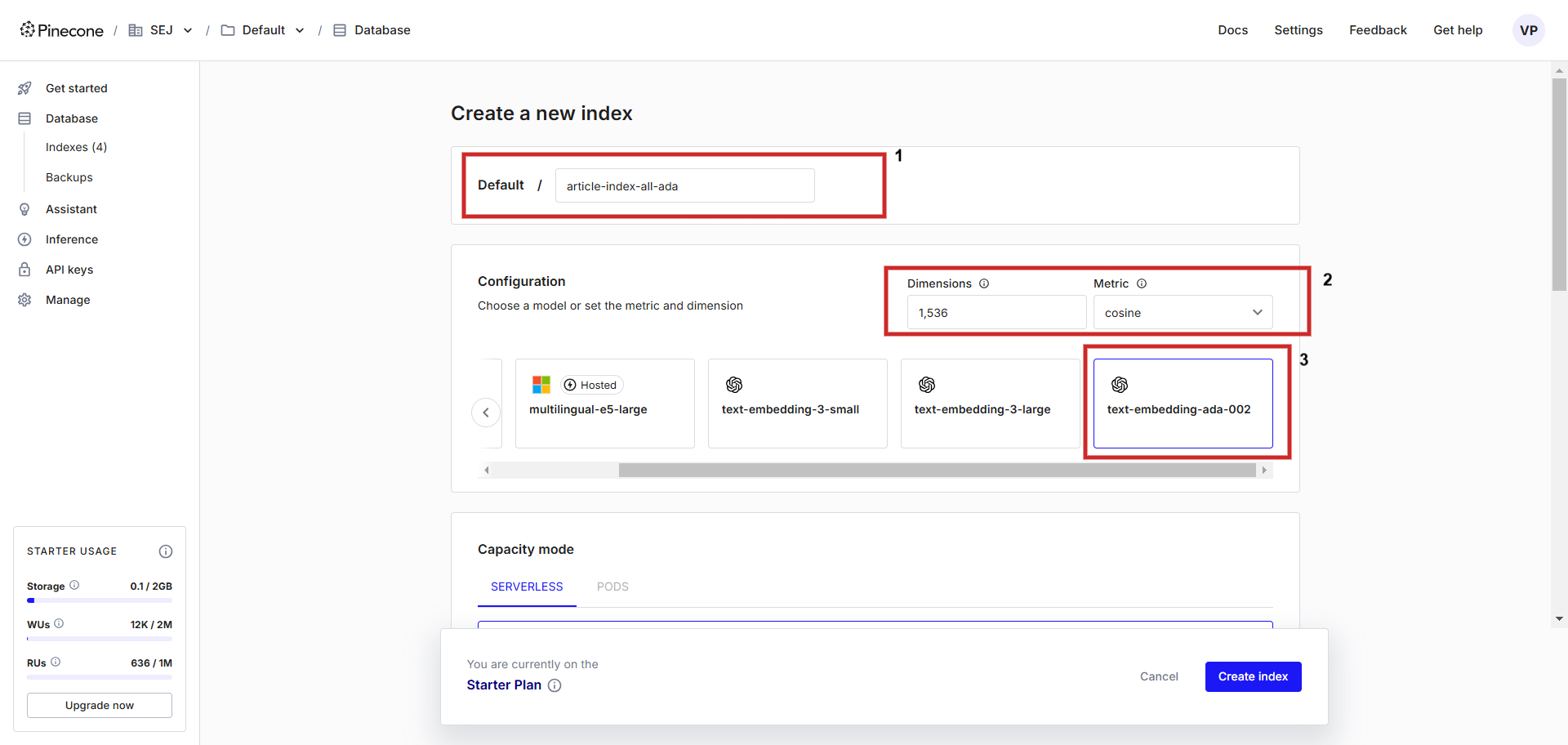 Creando una base de datos vectorial.
Creando una base de datos vectorial.Esta interfaz de usuario de Helper es solo para ayudarlo durante la configuración, en caso de que desee almacenar Vertex AI Vector Incrushding, necesita establecer ‘dimensiones’ en 768 en la pantalla de configuración manualmente para que coincida con la dimensionalidad predeterminada y puede almacenar vectores de texto de vértice (USTED usted puede establecer un valor de dimensión de 1 a 768 para guardar la memoria).
En este artículo aprenderemos cómo usar los modelos ‘Texting-ADA-002’ de OpenAI y el texto Vertex AI ‘Embedding-005’ ‘.
Una vez creado, necesitamos una clave API para poder conectarse a la base de datos utilizando una URL de host de la base de datos Vector.
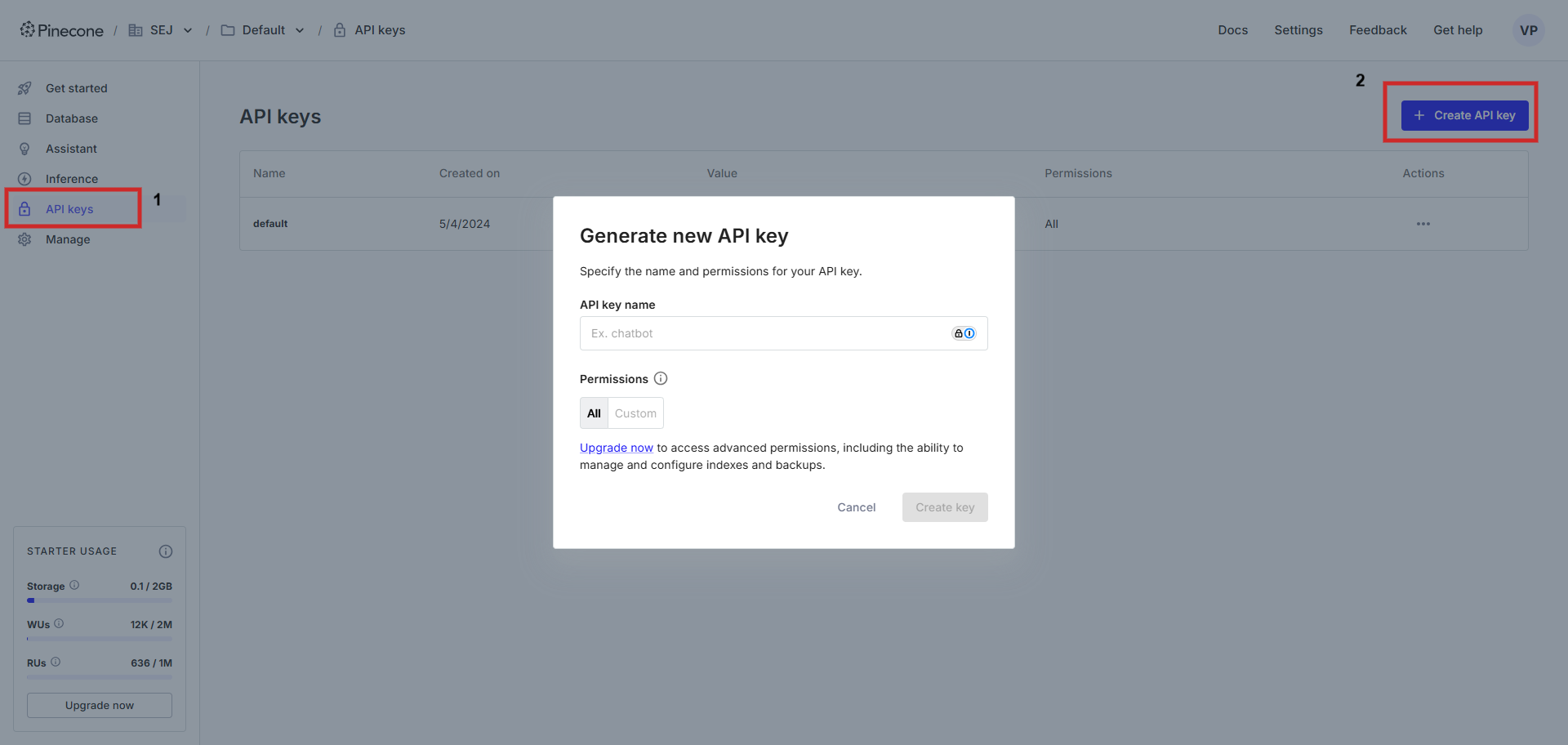
Generar una clave API
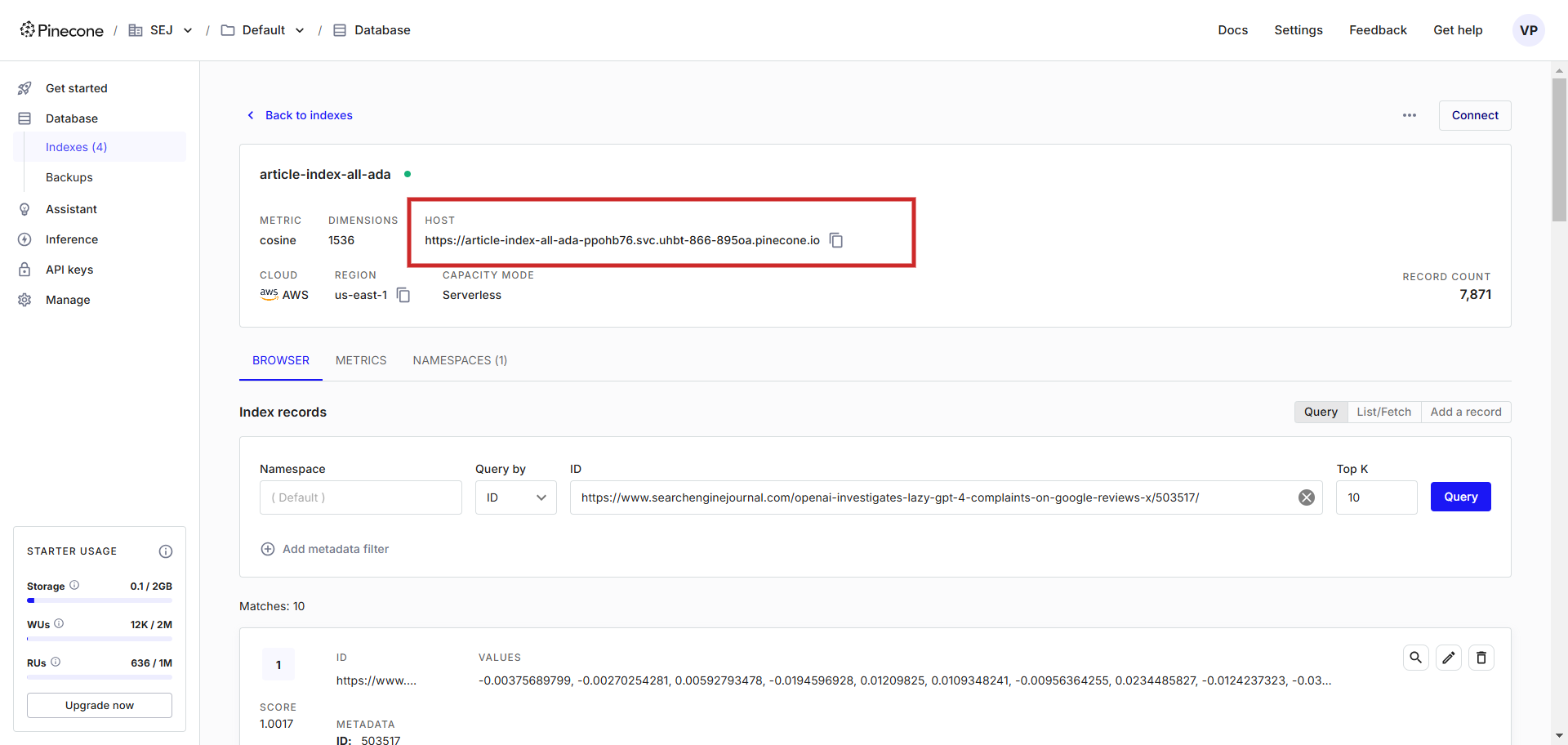
URL de host de la base de datos Vector
A continuación, deberá usar el cuaderno Jupyter. Si no lo tiene instalado, siga esta guía para instalarlo y ejecute este comando (a continuación) después en el terminal de su PC para instalar todos los paquetes necesarios.
pip install openai google-cloud-aiplatform google-auth pandas pinecone-client tabulate ipython numpy¡Y recuerde que ChatGPT es muy útil cuando te encuentras con los problemas durante la codificación!
2. Exporte sus artículos de su CMS
A continuación, necesitamos preparar un archivo de exportación de CSV de artículos de su CMS. Si usa WordPress, puede usar un complemento para hacer exportaciones personalizadas.
Como nuestro objetivo final es construir una herramienta de enlace interna, debemos decidir qué datos deben impulsarse a la base de datos de vectores como metadatos. Esencialmente, el filtrado basado en metadatos actúa como una capa adicional de guía de recuperación, alineándola con el marco general de RAG al incorporar el conocimiento externo, lo que ayudará a mejorar la calidad de la recuperación.
Por ejemplo, si estamos editando un artículo sobre “PPC” y queremos insertar un enlace a la frase “investigación de palabras clave”, podemos especificar en nuestra herramienta que “categoría = PPC”. Esto permitirá que la herramienta consulte solo artículos dentro de la categoría “PPC”, asegurando un enlace preciso y contextualmente relevante, o es posible que deseemos vincular a la frase “Actualización más reciente de Google” y limitar la coincidencia solo con artículos de noticias utilizando ‘Tipo ‘y publicado este año.
En nuestro caso, exportaremos:
- Título.
Categoría. - Tipo.
- Publicar fecha.
- Publicar año.
- Enlace permanente.
- Meta descripción.
- Contenido.
Para ayudar a devolver los mejores resultados, concatenaríamos los campos de título y meta descripciones, ya que son la mejor representación del artículo que podemos vectorizar e ideal para incrustar y fines de vinculación internos.
El uso del contenido completo del artículo para incrustaciones puede reducir la precisión y diluir la relevancia de los vectores.
Esto sucede porque una sola incrustación grande intenta representar múltiples temas cubiertos en el artículo a la vez, lo que lleva a una representación menos enfocada y relevante. Se deben aplicar estrategias de fragmentación (dividir el artículo por encabezados naturales o segmentos semánticamente significativos), pero estos no son el foco de este artículo.
Aquí está el archivo de exportación de muestra que puede descargar y usar para nuestra muestra de código a continuación.
2. Insertar los incrustaciones de texto de OpenAI en la base de datos Vector
Suponiendo que ya tenga una tecla API de OpenAI, este código generará incrustaciones de vectores desde el texto e insertará en la base de datos Vector en Pinecone.
import pandas as pd
from openai import OpenAI
from pinecone import Pinecone
from IPython.display import clear_output
# Setup your OpenAI and Pinecone API keys
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI client
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY')
# Connect to an existing Pinecone index
index_name = "article-index-all-ada"
index = pinecone.Index(index_name)
def generate_embeddings(text):
"""
Generates an embedding for the given text using OpenAI's API.
Returns None if text is invalid or an error occurs.
"""
try:
if not text or not isinstance(text, str):
raise ValueError("Input text must be a non-empty string.")
result = openai_client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
clear_output(wait=True) # Clear output for a fresh display
if hasattr(result, 'data') and len(result.data) > 0:
print("API Response:", result)
return result.data(0).embedding
else:
raise ValueError("Invalid response from the OpenAI API. No data returned.")
except ValueError as ve:
print(f"ValueError: {ve}")
return None
except Exception as e:
print(f"An error occurred while generating embeddings: {e}")
return None
# Load your articles from a CSV
df = pd.read_csv('Sample Export File.csv')
# Process each article
for idx, row in df.iterrows():
try:
clear_output(wait=True)
content = row("Content")
vector = generate_embeddings(content)
if vector is None:
print(f"Skipping article ID {row('ID')} due to empty or invalid embedding.")
continue
index.upsert(vectors=(
(
row('Permalink'), # Unique ID
vector, # The embedding
{
'title': row('Title'),
'category': row('Category'),
'type': row('Type'),
'publish_date': row('Publish Date'),
'publish_year': row('Publish Year')
}
)
))
except Exception as e:
clear_output(wait=True)
print(f"Error processing article ID {row('ID')}: {str(e)}")
print("Embeddings are successfully stored in the vector database.")
Debe crear un archivo de cuaderno y copiarlo y pegarlo allí, luego cargar el archivo CSV ‘Sample Exportar archivo.csv’ en la misma carpeta.
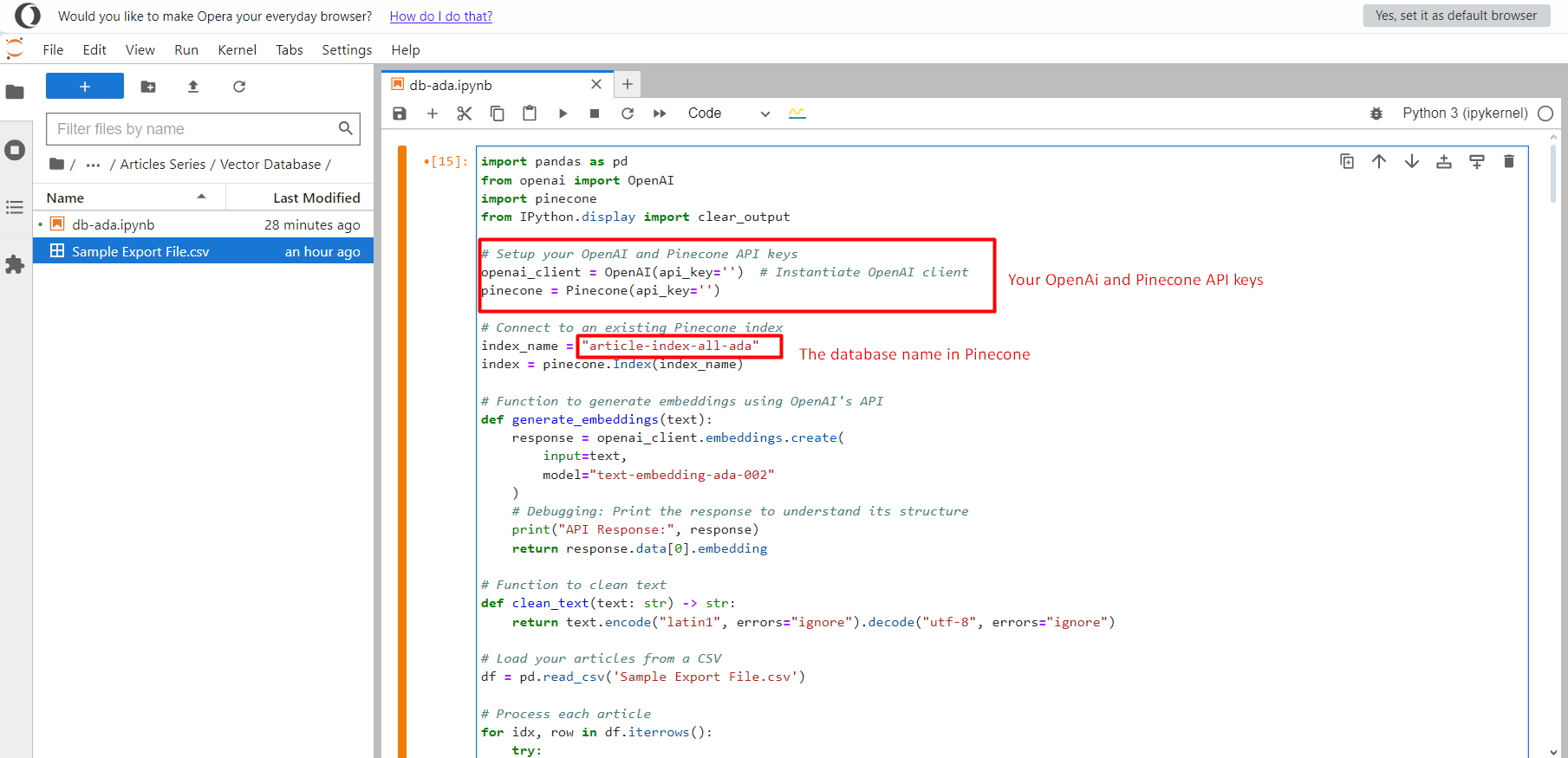 Proyecto Jupyter.
Proyecto Jupyter.Una vez hecho esto, haga clic en el botón Ejecutar y comenzará a presionar todos los vectores de texto en el índice article-index-all-ada Creamos en el primer paso.
 Ejecutando el script.
Ejecutando el script.Verá un texto de registro de salida de los vectores de incrustación. Una vez terminado, mostrará el mensaje al final que se terminó con éxito. Ahora vaya y consulte su índice en Pinecone y verá que sus registros están ahí.
3. Encontrar una coincidencia de artículo para una palabra clave
Bien, ahora intentemos encontrar una coincidencia de artículo para la palabra clave.
Cree un nuevo archivo de cuaderno y copie y pegue este código.
from openai import OpenAI
from pinecone import Pinecone
from IPython.display import clear_output
from tabulate import tabulate # Import tabulate for table formatting
# Setup your OpenAI and Pinecone API keys
openai_client = OpenAI(api_key='YOUR_OPENAI_API_KEY') # Instantiate OpenAI client
pinecone = Pinecone(api_key='YOUR_OPENAI_API_KEY')
# Connect to an existing Pinecone index
index_name = "article-index-all-ada"
index = pinecone.Index(index_name)
# Function to generate embeddings using OpenAI's API
def generate_embeddings(text):
"""
Generates an embedding for a given text using OpenAI's API.
"""
try:
if not text or not isinstance(text, str):
raise ValueError("Input text must be a non-empty string.")
result = openai_client.embeddings.create(
input=text,
model="text-embedding-ada-002"
)
# Debugging: Print the response to understand its structure
clear_output(wait=True)
#print("API Response:", result)
if hasattr(result, 'data') and len(result.data) > 0:
return result.data(0).embedding
else:
raise ValueError("Invalid response from the OpenAI API. No data returned.")
except ValueError as ve:
print(f"ValueError: {ve}")
return None
except Exception as e:
print(f"An error occurred while generating embeddings: {e}")
return None
# Function to query the Pinecone index with keywords and metadata
def match_keywords_to_index(keywords):
"""
Matches a list of keywords to the closest article in the Pinecone index, filtering by metadata dynamically.
"""
results = ()
for keyword_pair in keywords:
try:
clear_output(wait=True)
# Extract the keyword and category from the sub-array
keyword = keyword_pair(0)
category = keyword_pair(1)
# Generate embedding for the current keyword
vector = generate_embeddings(keyword)
if vector is None:
print(f"Skipping keyword '{keyword}' due to embedding error.")
continue
# Query the Pinecone index for the closest vector with metadata filter
query_results = index.query(
vector=vector, # The embedding of the keyword
top_k=1, # Retrieve only the closest match
include_metadata=True, # Include metadata in the results
filter={"category": category} # Filter results by metadata category dynamically
)
# Store the closest match
if query_results('matches'):
closest_match = query_results('matches')(0)
results.append({
'Keyword': keyword, # The searched keyword
'Category': category, # The category used for filtering
'Match Score': f"{closest_match('score'):.2f}", # Similarity score (formatted to 2 decimal places)
'Title': closest_match('metadata').get('title', 'N/A'), # Title of the article
'URL': closest_match('id') # Using 'id' as the URL
})
else:
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'N/A',
'Title': 'No match found',
'URL': 'N/A'
})
except Exception as e:
clear_output(wait=True)
print(f"Error processing keyword '{keyword}' with category '{category}': {e}")
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'Error',
'Title': 'Error occurred',
'URL': 'N/A'
})
return results
# Example usage: Find matches for an array of keywords and categories
keywords = (("SEO Tools", "SEO"), ("TikTok", "TikTok"), ("SEO Consultant", "SEO")) # Replace with your keywords and categories
matches = match_keywords_to_index(keywords)
# Display the results in a table
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
Estamos tratando de encontrar una coincidencia para estas palabras clave:
- Herramientas de SEO.
- Tiktok.
- Consultor de SEO.
Y este es el resultado que obtenemos después de ejecutar el código:
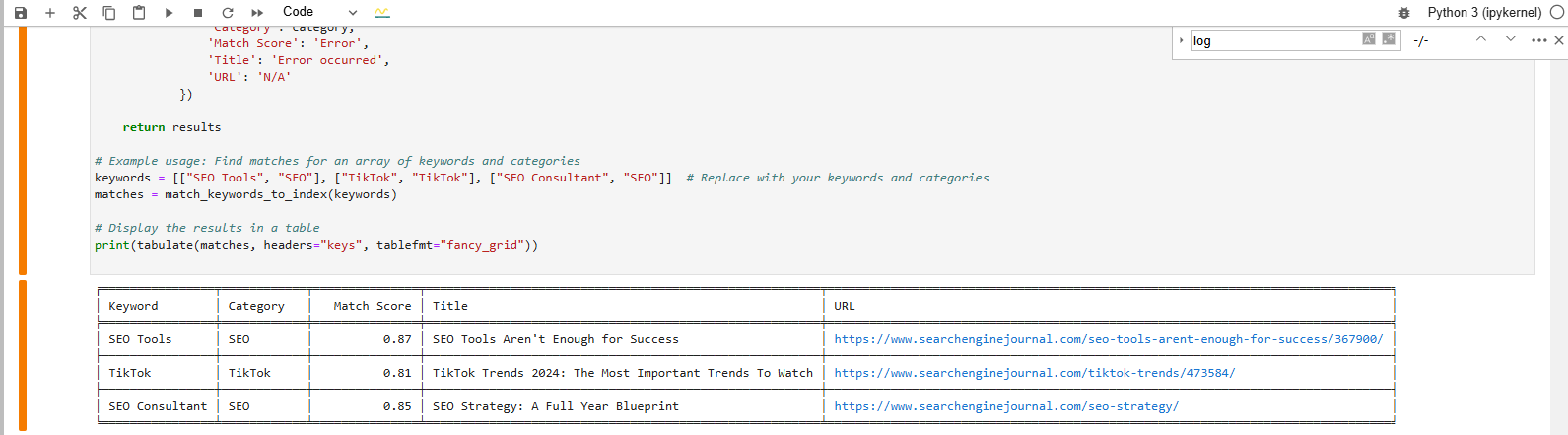 Encuentre una coincidencia para la frase de la palabra clave de la base de datos Vector
Encuentre una coincidencia para la frase de la palabra clave de la base de datos VectorLa salida formateada de la tabla en la parte inferior muestra la coincidencia del artículo más cercana con nuestras palabras clave.
4. Inserción de Google Vertex AI Text Incrusties en la base de datos de Vector
Ahora hagamos lo mismo pero con Google Vertex Ai ‘text-embedding-005‘incrustación. Este modelo es notable porque está desarrollado por Google, potencia la búsqueda de AI Vertex, y está específicamente capacitado para manejar tareas de recuperación y coincidencia de consultas, lo que lo hace bien adecuado para nuestro caso de uso.
Incluso puede crear un widget de búsqueda interna y agregarlo a su sitio web.
Comience iniciando sesión en Google Cloud Console y cree un proyecto. Luego, desde la biblioteca API, encuentre Vertex AI API y habilítelo.
 Captura de pantalla de Google Cloud Console, diciembre de 2024
Captura de pantalla de Google Cloud Console, diciembre de 2024Configure su cuenta de facturación para poder usar Vertex AI, ya que el precio es de $ 0.0002 por cada 1,000 caracteres (y ofrece créditos de $ 300 para nuevos usuarios).
Una vez que lo configura, debe navegar a API Services> Credenciales Crear una cuenta de servicio, generar una clave y descargarlas como JSON.
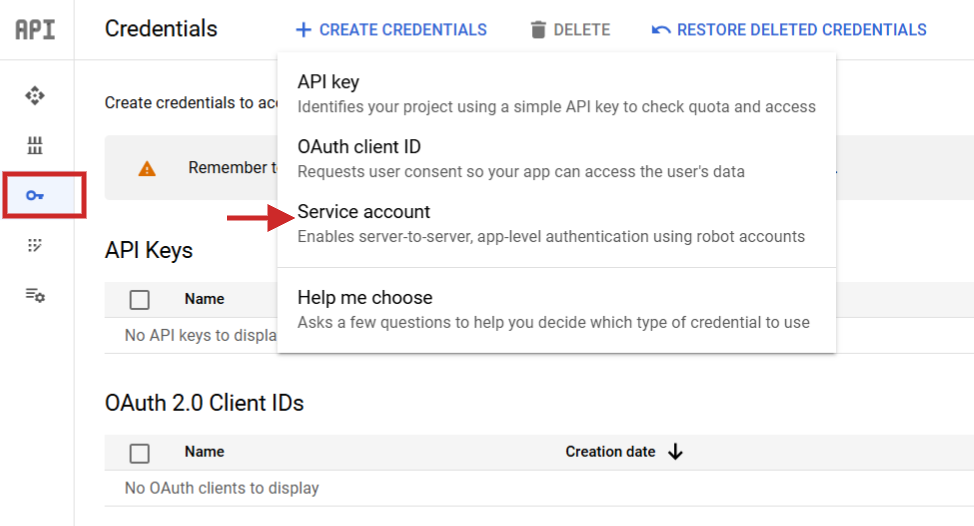
Paso 1: crear un servicio una cuenta
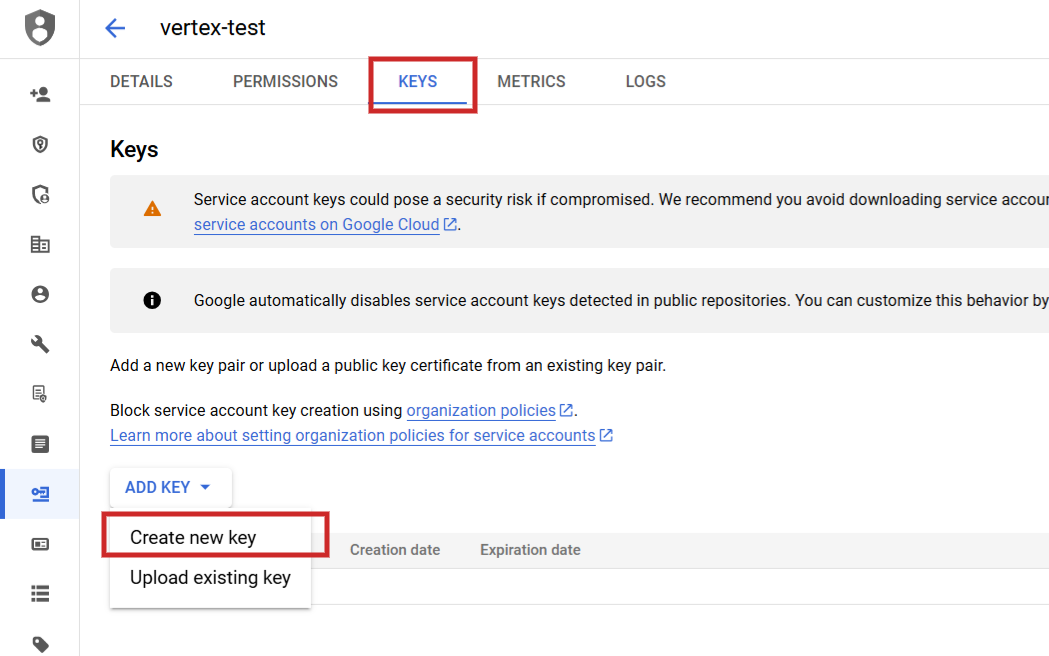
Paso 2: Agregar nueva clave en la cuenta de teclas de la cuenta de servicio

Paso 3: crear una clave JSON
Cambie el nombre del archivo JSON a config.json y cárguelo (a través del icono de flecha) a su carpeta del proyecto Jupyter Notebook.
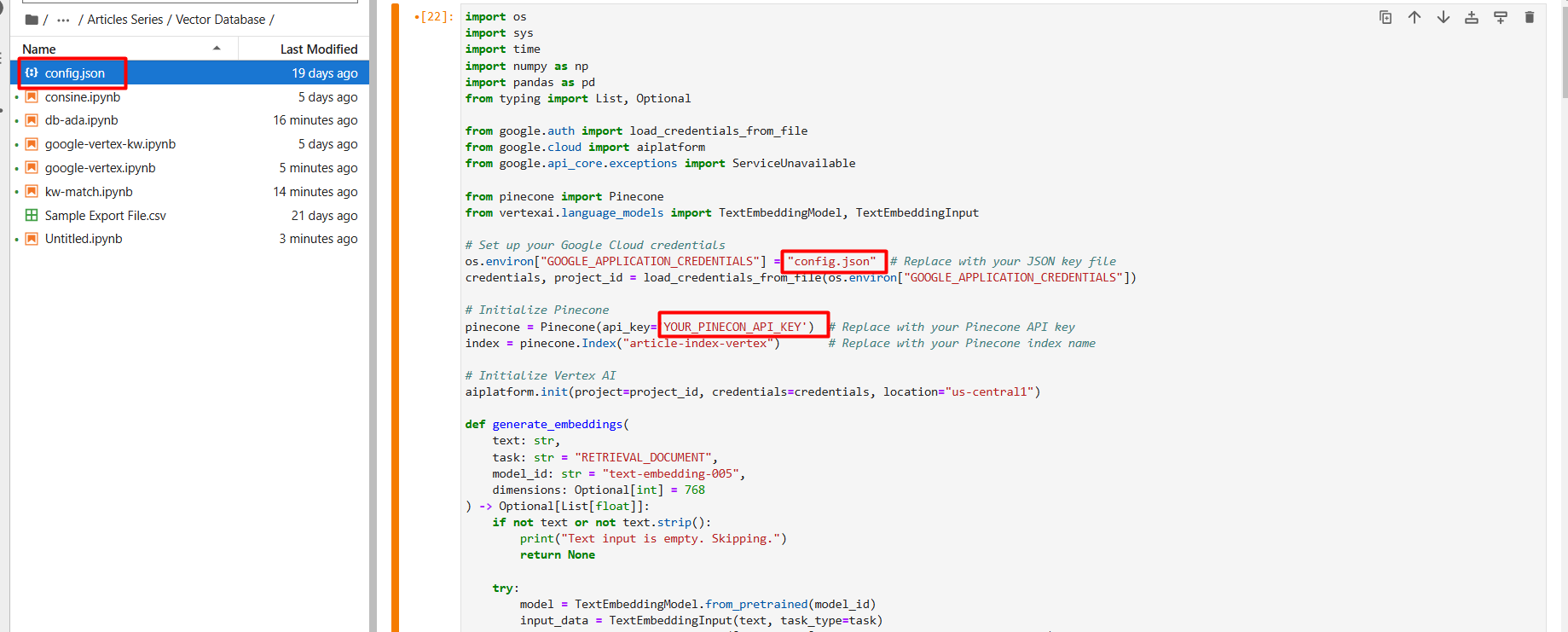 Captura de pantalla de Google Cloud Console, diciembre de 2024
Captura de pantalla de Google Cloud Console, diciembre de 2024En el primer paso de configuración, cree una nueva base de datos vectorial llamada Artículo-Index-Viex configurando Dimension 768 manualmente.
Una vez creado, puede ejecutar este script para comenzar a generar embedidas vectoriales del mismo archivo de muestra usando Google Vertex AI text-embedding-005 Modelo (puede elegir Text-Multilingüe-Embedding-002 si tiene texto que no tiene inglés).
import os
import sys
import time
import numpy as np
import pandas as pd
from typing import List, Optional
from google.auth import load_credentials_from_file
from google.cloud import aiplatform
from google.api_core.exceptions import ServiceUnavailable
from pinecone import Pinecone
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
# Set up your Google Cloud credentials
os.environ("GOOGLE_APPLICATION_CREDENTIALS") = "config.json" # Replace with your JSON key file
credentials, project_id = load_credentials_from_file(os.environ("GOOGLE_APPLICATION_CREDENTIALS"))
# Initialize Pinecone
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Replace with your Pinecone API key
index = pinecone.Index("article-index-vertex") # Replace with your Pinecone index name
# Initialize Vertex AI
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
text: str,
task: str = "RETRIEVAL_DOCUMENT",
model_id: str = "text-embedding-005",
dimensions: Optional(int) = 768
) -> Optional(List(float)):
if not text or not text.strip():
print("Text input is empty. Skipping.")
return None
try:
model = TextEmbeddingModel.from_pretrained(model_id)
input_data = TextEmbeddingInput(text, task_type=task)
vectors = model.get_embeddings((input_data), output_dimensionality=dimensions)
return vectors(0).values
except ServiceUnavailable as e:
print(f"Vertex AI service is unavailable: {e}")
return None
except Exception as e:
print(f"Error generating embeddings: {e}")
return None
# Load data from CSV
data = pd.read_csv("Sample Export File.csv") # Replace with your CSV file path
for idx, row in data.iterrows():
try:
permalink = str(row("Permalink"))
content = row("Content")
embedding = generate_embeddings(content)
if not embedding:
print(f"Skipping article ID {row('ID')} due to empty or failed embedding.")
continue
print(f"Embedding for {permalink}: {embedding(:5)}...")
sys.stdout.flush()
index.upsert(vectors=(
(
permalink,
embedding,
{
'category': row('Category'),
'title': row('Title'),
'publish_date': row('Publish Date'),
'type': row('Type'),
'publish_year': row('Publish Year')
}
)
))
time.sleep(1) # Optional: Sleep to avoid rate limits
except Exception as e:
print(f"Error processing article ID {row('ID')}: {e}")
print("All embeddings are stored in the vector database.")
Verá a continuación en registros de incrustaciones creadas.
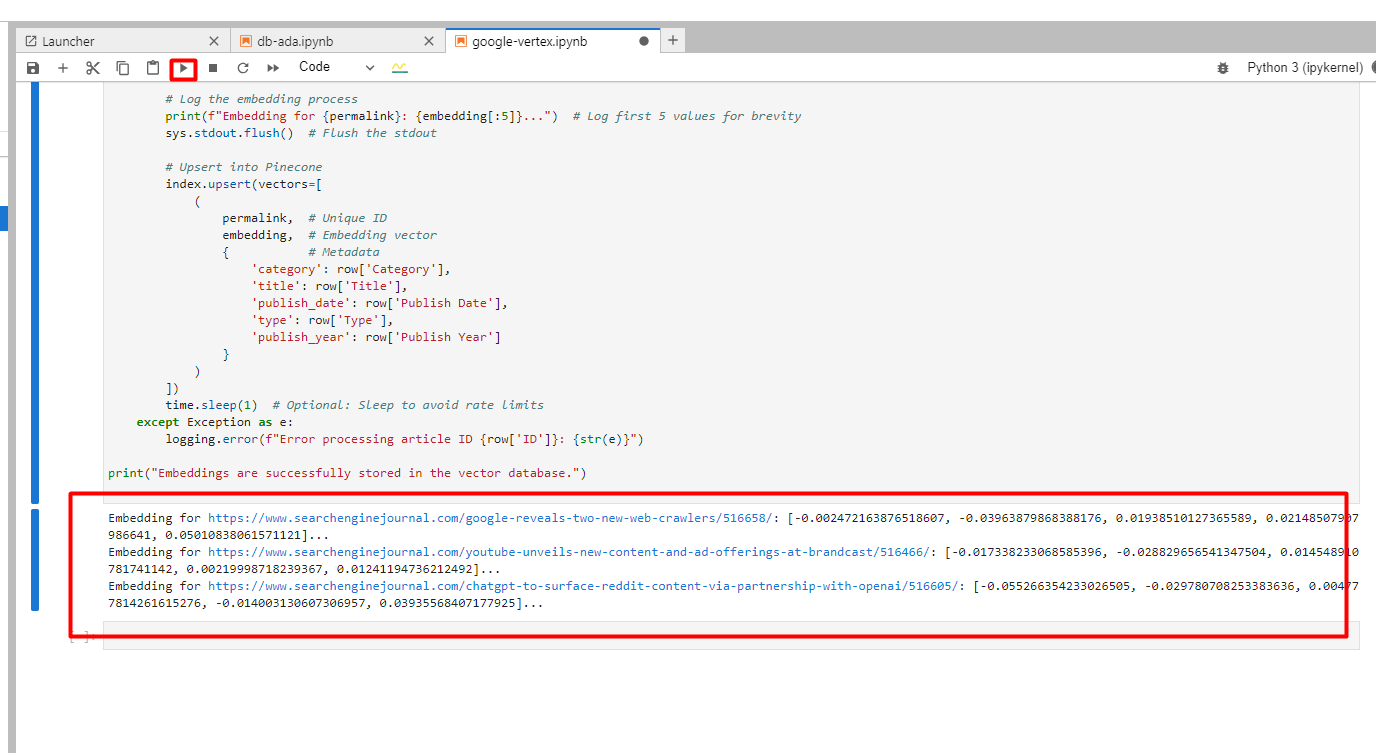 Captura de pantalla de Google Cloud Console, diciembre de 2024
Captura de pantalla de Google Cloud Console, diciembre de 20244. Encontrar una coincidencia de artículo para una palabra clave usando Google Vertex AI
Ahora, hagamos la misma palabra clave que coincide con Vertex Ai. Hay un pequeño matiz, ya que debe usar ‘Recuperal_query’ vs. ‘Recuperal_Document’ como un argumento al generar incrustaciones de palabras clave mientras estamos tratando de realizar una búsqueda de un artículo (también conocido como documento) que mejor coincida con nuestra frase.
Los tipos de tareas son una de las ventajas importantes que el Vertex Ai tiene sobre los modelos de OpenAI.
Asegura que las incrustaciones capturen la intención de las palabras clave que es importante para la vinculación interna, y mejora la relevancia y precisión de las coincidencias que se encuentran en su base de datos vectorial.
Use este script para hacer coincidir las palabras clave con los vectores.
import os
import pandas as pd
from google.cloud import aiplatform
from google.auth import load_credentials_from_file
from google.api_core.exceptions import ServiceUnavailable
from vertexai.language_models import TextEmbeddingModel
from pinecone import Pinecone
from tabulate import tabulate # For table formatting
# Set up your Google Cloud credentials
os.environ("GOOGLE_APPLICATION_CREDENTIALS") = "config.json" # Replace with your JSON key file
credentials, project_id = load_credentials_from_file(os.environ("GOOGLE_APPLICATION_CREDENTIALS"))
# Initialize Pinecone client
pinecone = Pinecone(api_key='YOUR_PINECON_API_KEY') # Add your Pinecone API key
index_name = "article-index-vertex" # Replace with your Pinecone index name
index = pinecone.Index(index_name)
# Initialize Vertex AI
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
def generate_embeddings(
text: str,
model_id: str = "text-embedding-005"
) -> list:
"""
Generates embeddings for the input text using Google Vertex AI's embedding model.
Returns None if text is empty or an error occurs.
"""
if not text or not text.strip():
print("Text input is empty. Skipping.")
return None
try:
model = TextEmbeddingModel.from_pretrained(model_id)
vector = model.get_embeddings((text)) # Removed 'task_type' and 'output_dimensionality'
return vector(0).values
except ServiceUnavailable as e:
print(f"Vertex AI service is unavailable: {e}")
return None
except Exception as e:
print(f"Error generating embeddings: {e}")
return None
def match_keywords_to_index(keywords):
"""
Matches a list of keyword-category pairs to the closest articles in the Pinecone index,
filtering by metadata if specified.
"""
results = ()
for keyword_pair in keywords:
keyword = keyword_pair(0)
category = keyword_pair(1)
try:
keyword_vector = generate_embeddings(keyword)
if not keyword_vector:
print(f"No embedding generated for keyword '{keyword}' in category '{category}'.")
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'Error/Empty',
'Title': 'No match',
'URL': 'N/A'
})
continue
query_results = index.query(
vector=keyword_vector,
top_k=1,
include_metadata=True,
filter={"category": category}
)
if query_results('matches'):
closest_match = query_results('matches')(0)
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': f"{closest_match('score'):.2f}",
'Title': closest_match('metadata').get('title', 'N/A'),
'URL': closest_match('id')
})
else:
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'N/A',
'Title': 'No match found',
'URL': 'N/A'
})
except Exception as e:
print(f"Error processing keyword '{keyword}' with category '{category}': {e}")
results.append({
'Keyword': keyword,
'Category': category,
'Match Score': 'Error',
'Title': 'Error occurred',
'URL': 'N/A'
})
return results
# Example usage:
keywords = (("SEO Tools", "Tools"), ("TikTok", "TikTok"), ("SEO Consultant", "SEO"))
matches = match_keywords_to_index(keywords)
# Display the results in a table
print(tabulate(matches, headers="keys", tablefmt="fancy_grid"))
Y verás puntajes generados:
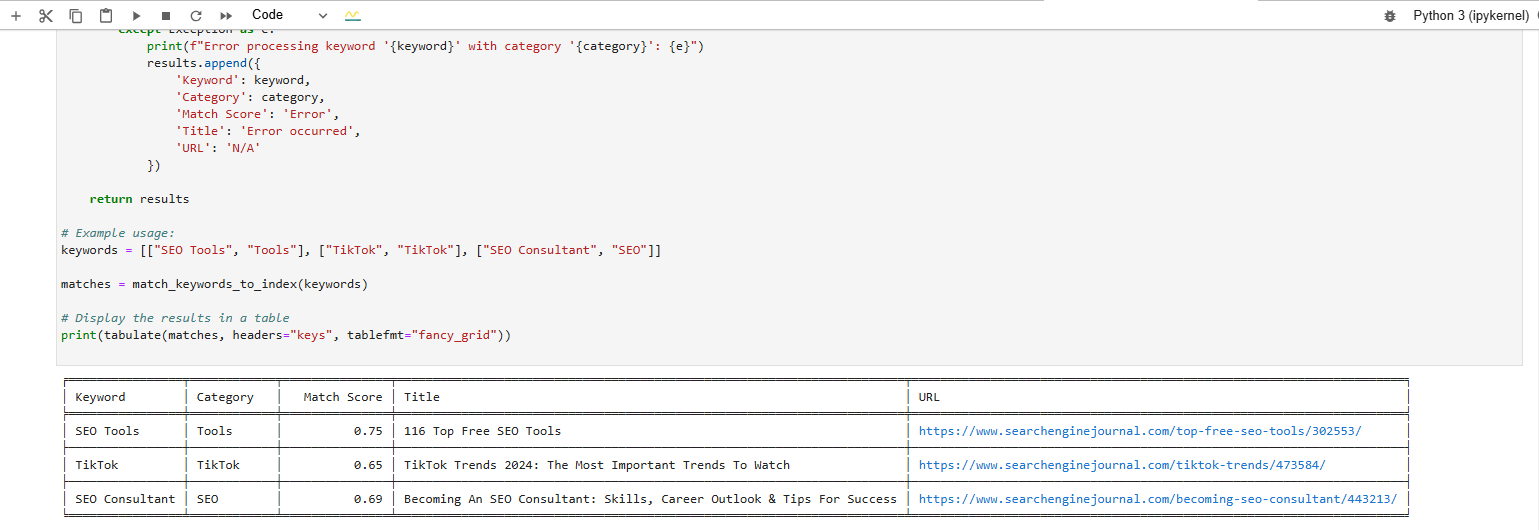 Puntuaciones de palabras clave Mate producidas por Vertex AI Text Incrustando el modelo
Puntuaciones de palabras clave Mate producidas por Vertex AI Text Incrustando el modeloIntente probar la relevancia de su artículo
Piense en esto como una forma simplificada (amplia) de verificar cuán semánticamente similar es su escritura para la palabra clave de la cabeza. Cree una incrustación vectorial de la palabra clave de su cabeza y contenido completo del artículo a través de la IA de vértices de Google y calcule una similitud de coseno.
Si su texto es demasiado largo, es posible que deba considerar la implementación de estrategias de fragmentación.
Una puntuación cercana (similitud de coseno) a 1.0 (como 0.8 o 0.7) significa que está bastante cerca de ese tema. Si su puntaje es más bajo, puede encontrar que una introducción excesivamente larga que tiene mucha pelusa puede estar causando dilución de la relevancia y el corte ayuda a aumentarla.
Pero recuerde, cualquier edición realizada debe tener sentido desde una perspectiva editorial y de experiencia del usuario también.
Incluso puede hacer una comparación rápida incrustando el contenido de alto rango de un competidor y viendo cómo se acumula.
Hacer esto le ayuda a alinear con mayor precisión su contenido con el sujeto objetivo, lo que puede ayudarlo a clasificarse mejor.
Ya hay herramientas que realizan tales tareas, pero aprender estas habilidades significa que puede adoptar un enfoque personalizado adaptado a sus necesidades y, por supuesto, hacerlo de forma gratuita.
Experimentar por usted mismo y aprender estas habilidades lo ayudará a seguir adelante con AI SEO y tomar decisiones informadas.
Como lecturas adicionales, te recomiendo que te sumerjas en estos grandes artículos:
Más recursos:
Imagen destacada: Aozorastock/Shutterstock
(Tagstotranslate) SEO (T) Aprendizaje automático

{kind=link}