

Todo esto se basa en la filtración de Google y concuerda con mi experiencia con contenido que funciona bien en Discover con el tiempo. Saqué los que creo que son los servidores proxy de Discover más destacados y los agrupé en lo que parece ser el flujo de trabajo apropiado.
Como un empleado de la BBC deshonrado, los pensamientos son míos.
TL;DR
- Su sitio debe ser visto como un “fuente confiable” con bajo SPAM, evaluado por proxies como puntuación de confianza del editor, para poder ser elegible.
- Discover está impulsado por un proceso de seis partes, que utiliza clics buenos versus malos (tiempo de permanencia prolongado frente a pogo-sticking) y repetir visitas para calificar y volver a calificar continuamente la calidad del contenido.
- El contenido nuevo recibe un impulso inicial. El éxito depende de un CTR sólido y positivo. compromiso en las primeras etapas (Los buenos clics/compartidos de todos los canales cuentan, no solo de Discover).
- Se prioriza el contenido que se alinea con los intereses del usuario. Para optimizar, concéntrese en sus áreas de autoridad temática, utilice titulares convincentes, esté basado en entidades y utilice imágenes grandes (más de 1200 px).
Cuento 15 proxies diferentes que Google utiliza para satisfacer la desesperada necesidad de contenido de calidad en el feed de Discover de los doomscrollers. Que no es eso diferente a cómo funciona la búsqueda tradicional de Google.
Pero la búsqueda tradicional (un canal de atracción de alta calidad) está muy lejos de Discover. El público mata el tiempo en los trenes. En sus suegros. El baño. Dado que son parte del mismo ecosistema, están agrupados en una entidad monolítica.
Y así es como funciona.
 Crédito de la imagen: Harry Clarkson-Bennett
Crédito de la imagen: Harry Clarkson-BennettDirectrices de descubrimiento de Google
Esta sección es aburrida y las pautas de Google sobre la elegibilidad son excepcionalmente vagas:
- El contenido es automáticamente elegible para aparecer en Discover si está indexado por Google y cumple con las políticas de contenido de Discover.
- Se filtra cualquier tipo de contenido peligroso, spam, engañoso o violento/vulgar.
“… Discover utiliza muchas de las mismas señales y sistemas utilizados por Search para determinar qué es… contenido útil, confiable y centrado en las personas”.
Luego dan algunos consejos sólidos, aunque beige, sobre títulos de calidad: clicables, no atractivos como diría John Shehata. Asegúrese de que su imagen destacada tenga al menos 1200 px de ancho y cree contenido oportuno y de valor agregado.
Pero podemos hacerlo mejor.
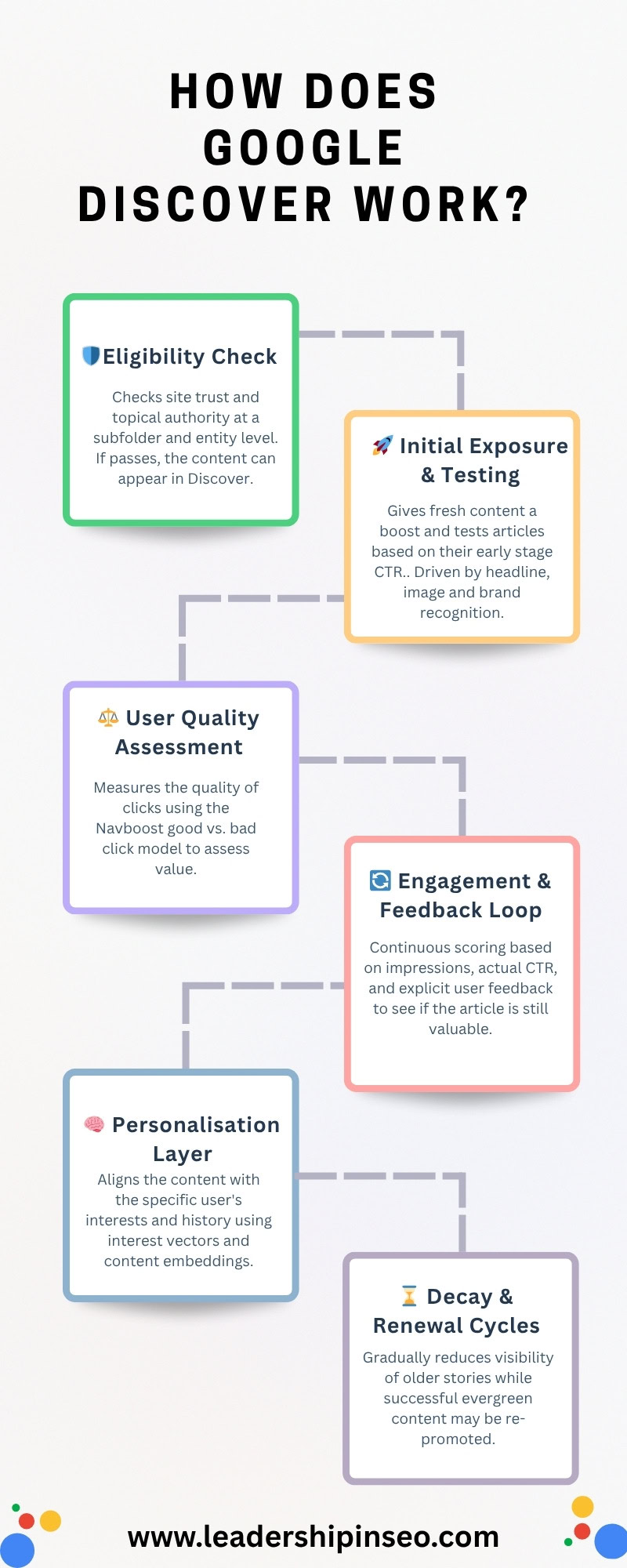
Canal de contenido de seis partes de Discover
Desde la cuna hasta la tumba, revisemos exactamente cómo aparece o, en la mayoría de los casos, no aparece su contenido en Discover. Como siempre, recuerde que inventé estos grupos, aunque basados en proxies reales de Google a partir de la filtración de Google.
- Verificación de elegibilidad y filtrado de referencia.
- Exposición inicial y pruebas.
- Evaluación de la calidad del usuario.
- Bucle de participación y retroalimentación.
- Capa de personalización.
- Ciclos de decadencia y renovación.
Elegibilidad y filtrado de referencia
Para empezar, su sitio debe ser elegible para Google Discover. Esto significa que usted es visto como una “fuente confiable” sobre el tema y tiene una puntuación de SPAM lo suficientemente baja como para que no se active el umbral.
Hay tres puntuaciones de proxy principales para tener en cuenta la elegibilidad y el filtrado de referencia:
- is_discover_feed_eligible: una característica booleana que filtra páginas no elegibles.
- Publisher_trustPuntuación: una puntuación que evalúa la confiabilidad y reputación del editor.
- topicAuthority_discover: una puntuación que ayuda a Discover a identificar fuentes confiables a nivel de tema.
La reputación del sitio y la autoridad temática se clasifican según el tema en cuestión. Estas tres métricas ayudan a evaluar si su sitio es apto para aparecer en Discover.
Exposición inicial y pruebas
Esta es en gran medida la etapa de frescura, donde el contenido nuevo recibe un impulso temporal (porque es más probable que el contenido contemporáneo sacie una mente adicta a la dopamina).
- frescuraBoost_discover: proporciona un impulso temporal para el contenido nuevo para mantener vivo el feed.
- descubrir_clics: donde los clics en artículos en las primeras etapas se utilizan como predictor de popularidad.
- títuloClickModel_discover: es un modelo predictivo de CTR basado en el título y la imagen.
Yo plantearía la hipótesis de que, al utilizar un modelo predictivo de estilo bayesiano, Google aplica lo aprendido a nivel de sitio y subcarpeta para predecir el CTR probable. Cuanto más contenido de calidad haya publicado a lo largo del tiempo (presumiblemente a nivel de sitio, subcarpeta y autor), más probabilidades tendrá de aparecer.
Porque hay menos ambigüedad. Una característica clave del SEO ahora.
Evaluación de la calidad del usuario
En última instancia, un artículo se juzga por la calidad de la participación del usuario. Google utiliza el modelo de estilo de clics buenos y malos de Navboost para establecer qué funciona y qué no funciona para los usuarios. El CTR bajo y/o el comportamiento de estilo pogo-sticking reducen las posibilidades de que un artículo aparezca.
El contenido valioso se decide por la proporción de clics buenos y malos. Las visitas repetidas se utilizan para medir la satisfacción duradera y volver a clasificar el contenido de mejor rendimiento.
- descubrir_lista_negra_puntuación: Sanción por spam, desinformación o clickbait.
- buenosClicks_discover: Interacciones positivas con el usuario (largo tiempo de permanencia).
- badClicks_discover: Interacciones negativas (rebotes, permanencia breve).
- nav_boosted_discover_clicks: Métrica de participación repetida o devuelta.
Luego, la calidad del artículo se mide por la participación de los usuarios. Como Discover es una plataforma personalizada, esto se puede hacer de forma precisa y a escala. Se pueden agrupar cohortes de usuarios. Las personas con los mismos intereses generales reciben el contenido si, según el estándar del algoritmo, deberían estar interesadas.
Pero si el título engañoso o que hace demasiado clic genera poca participación (tiempo de permanencia e interacciones en la página), entonces el artículo puede ser degradado. Con el tiempo, este tipo de práctica puede agravar y debilitar completamente su sitio.
 Titulares como este son un boleto de ida para devaluar su marca ante los ojos de las personas y los motores de búsqueda (Crédito de la imagen: Harry Clarkson-Bennett)
Titulares como este son un boleto de ida para devaluar su marca ante los ojos de las personas y los motores de búsqueda (Crédito de la imagen: Harry Clarkson-Bennett)Es importante tener en cuenta que estos datos de clics no tienen que provenir de Discover. Una vez que un artículo sale a la luz (se publica, se comparte en las redes sociales, etc.), los datos de clics de Chrome se almacenan y se aplican al algoritmo.
Por lo tanto, cuantos más datos de clics y recursos compartidos de calidad pueda generar al principio del ciclo de vida de un artículo (teniendo en cuenta la importancia de la actualización), mayores serán sus posibilidades de éxito en Discover. Trátalo como una plataforma viral. Haz ruido. hacer marketing.
Bucle de participación y retroalimentación
Una vez que el artículo entra en la proverbial refriega, comienza un ciclo de puntuación y recuperación. El CTR continuo, las impresiones y los comentarios explícitos de los usuarios (como botones de estilo, odio y “no me muestres esto otra vez, por favor”) alimentan modelos como Navboost para refinar lo que se muestra.
- descubrir_impresiones: La cantidad de veces que aparece un artículo en un feed de Discover.
- descubrir_ctr: Clics divididos por impresiones. Modelado de CTR de feeds de datos de impresiones y clics
- descubrir_feedback_negativo: Los comentarios específicos de los usuarios, es decir, no interesados, suprimen el contenido para individuos, grupos y en la plataforma en su conjunto.
Estas señales de comportamiento definen el éxito de un artículo. Vive o muere según métricas relativamente simples. Y cuanto más lo usas, mejor se vuelve. Porque sabe en qué es más probable que usted y su cohorte hagan clic y disfruten.
 Esto es tan cierto en Discover como en el algoritmo principal. Google lo admitió como tal en las sentencias del DoJ. (Crédito de la imagen: Harry Clarkson-Bennett)
Esto es tan cierto en Discover como en el algoritmo principal. Google lo admitió como tal en las sentencias del DoJ. (Crédito de la imagen: Harry Clarkson-Bennett)Me imagino que los datos de titulares e imágenes se almacenan para que el algoritmo pueda aplicar algunos estándares rigurosos al modelado estadístico. Una vez que se sabe qué tipos de titulares, imágenes y artículos funcionan mejor para grupos específicos, la personalización se vuelve efectiva más rápidamente.
Capa de personalización
Google sabe mucho sobre nosotros. En eso se basa su negocio. Recopila una gran cantidad de datos no anonimizados (datos de tarjetas de crédito, contraseñas, datos de contacto, etc.) junto con cada interacción imaginable que tenga con las páginas web.
Discover lleva la personalización al siguiente nivel. Creo que puede ofrecer una idea de cómo podría verse parte del SERP en el futuro. Un grupo personalizado de artículos, vídeos y publicaciones sociales diseñados para engancharte, integrados en algún lugar junto a los resultados de búsqueda y el modo AI.
Todo esto está diseñado para mantenerte en las propiedades de Google por más tiempo. Porque así ganan más dinero.
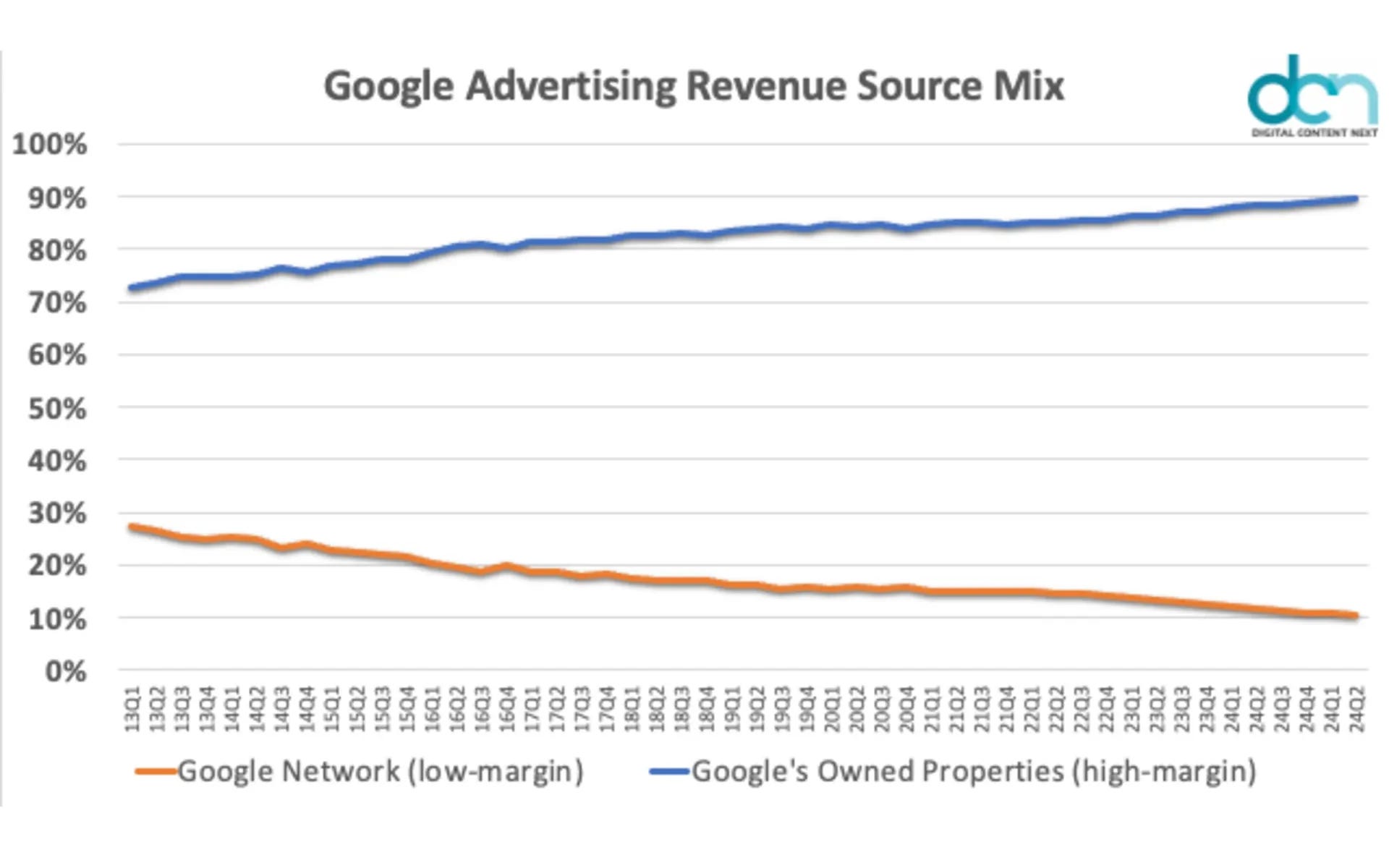 Pista: quieren retenerte porque ganan más dinero (Crédito de la imagen: Harry Clarkson-Bennett)
Pista: quieren retenerte porque ganan más dinero (Crédito de la imagen: Harry Clarkson-Bennett)- contentEmbeddings_discover: Las incrustaciones de contenido determinan qué tan bien se alinea el contenido con los intereses del usuario. Esto impulsa el motor de coincidencia de intereses de Discover.
- personalización_vector_match: Este módulo personaliza dinámicamente el feed del usuario en tiempo real. Identifica similitud entre el contenido y los vectores de interés del usuario.
El contenido que coincida bien con sus intereses personales y de su cohorte se incluirá en su feed.
Puede ver los sitios con los que interactúa con frecuencia utilizando la página de participación del sitio en Chrome (desde su barra de herramientas: chrome://site-engagement/) y cada interacción almacenada con histogramas. Estos datos de histograma muestran indirectamente los puntos de interacción clave que tiene con las páginas web, midiendo la respuesta y el rendimiento del navegador en torno a esas interacciones.
No dice explícitamente el usuario A hizo clic en Xpero registra el impacto técnico, es decir, cuánto tiempo pasó el navegador procesando dicho clic o desplazamiento.
Ciclos de decadencia y renovación
Discover aumenta la frescura porque la gente tiene sed de ella. Al impulsar el contenido nuevo, las historias más antiguas o saturadas decaen naturalmente a medida que avanza el ciclo de noticias y disminuye la participación del artículo.
En el caso de las historias exitosas, esto se debe a la saturación del mercado.
- frescuraDecay_timer: Este módulo mide la decadencia de la actualidad después de la exposición inicial, reduciendo gradualmente la visibilidad para dar paso a contenido más nuevo.
- content_staleness_penalty: El contenido o los temas obsoletos reciben una prioridad menor una vez que la participación comienza a disminuir para mantener el feed actualizado.
Discover es la respuesta de Google a una red social. Ninguno de nosotros pasa tiempo en Google. Que no es divertido. Utilizo la palabra diversión a la ligera. No está diseñado para engancharnos y arruinar nuestra capacidad de atención con aumentos constantes de dopamina.
Pero Google Discover está claramente en camino de lograrlo. Quieren convertirlo en un destino. De ahí todos los cambios recientes que le permiten “ponerse al día” con los creadores y editores que le interesan en múltiples plataformas.
Vídeos, publicaciones en redes sociales, artículos… los nueve metros completos. Sin embargo, desearía que dejaran de resumir literalmente todo con IA.
Mi flujo de trabajo de 11 pasos para aprovechar Google Discover al máximo
Siga los principios básicos y será de gran utilidad. Comprenda dónde su sitio es tópico fuerte y concentre su tiempo en el contenido que generará valor. Hay varias formas de hacer esto.
Si no aparece mucho en Discover, puede utilizar los datos de impresiones y clics de Search Console para identificar áreas donde genera el mayor valor. Donde eres tópicamente autoritario. Haría esto a nivel de subcarpeta y entidad (por ejemplo, política y Rachel Reeves o el Partido Laborista).
También vale la pena desglosarlo en total y por artículo. O puede utilizar algo como el informe Traffic Share de Ahrefs para determinar su cuota de voz a través de datos de terceros.
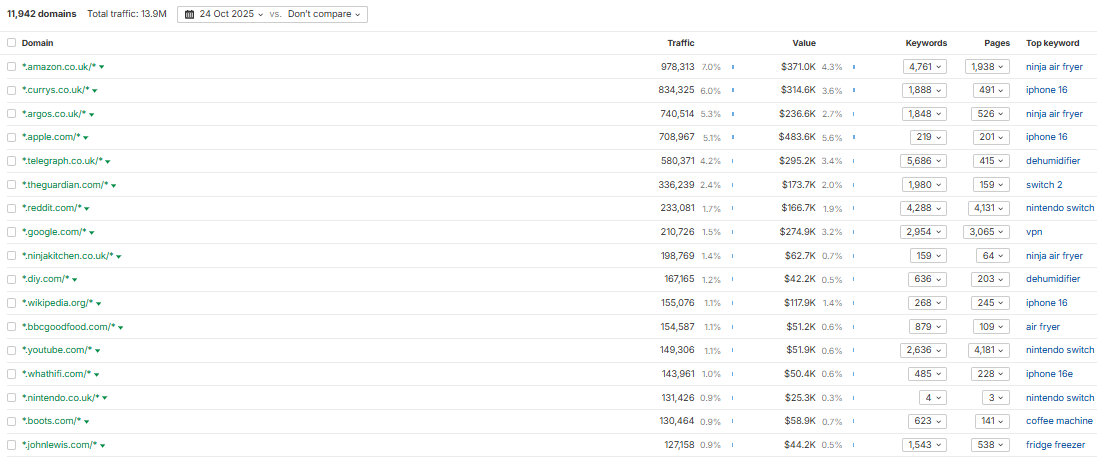 Básicamente, compartir datos de voz (Crédito de la imagen: Harry Clarkson-Bennett)
Básicamente, compartir datos de voz (Crédito de la imagen: Harry Clarkson-Bennett)Luego, realmente concentre su tiempo en a) áreas en las que ya tiene autoridad y b) áreas que generan valor. para tu audiencia.
Suponiendo que no te estás centrando en el contenido NSFW y eres vagamente elegible, esto es lo que yo haría:
- Asegúrate de reunirte requisito básico de imagens. 1200 píxeles de ancho como mínimo.
- Identifique sus áreas de autoridad temática. ¿Dónde se clasifica ya de manera efectiva a nivel de subcarpeta? ¿Hay algún autor específico que se desempeñe mejor? Intente aprovechar sus valiosos centros de contenido con contenido que debería generar valor adicional en esta área.
- Comprar Contenido que generará valor real. (vínculos y participación) en estas áreas. No persiga clics a través de Discover. Es un billete de ida a la ciudad del clickbait.
- Asegúrate de que estás conectado al ciclo de noticias. Ser el primero tiene un gran impacto en la visibilidad de las noticias en las búsquedas. Si no eres el primero en llegar a la escena, asegúrate de agregar algo adicional a la conversación. Sea audaz. Añade valor. Comprenda cómo funciona realmente el SEO de noticias.
- Estar impulsado por entidades. En sus titulares, primer párrafo, subtítulos, datos estructurados y texto alternativo de la imagen. Su página debe eliminar la ambigüedad. Debes dejar increíblemente claro de quién se trata esta página. La falta de claridad es en parte la razón por la que Google reescribe los titulares.
- Utilice el título Open Graph. El título OG es un titular que no aparece en su página. Diseñado principalmente para uso en redes sociales, es uno de los titulares más utilizados en Discover. Puede ser llamativo. La curiosidad llevó. Rico. Interesante. Pero todavía centrado en la entidad.
- Asegúrate de compartir contenido que probablemente tenga buenos resultados en Discover a través de canales de empuje relevantes al principio de su ciclo de vida. Necesita superar su desempeño previsto en las primeras etapas.*
- Crear una buena experiencia en la pagina. Su página (y sitio) debe ser rápido, seguro, publicitario y memorable por las razones correctas.
- intenta conducir viajes posteriores de calidad. Si puede tratar a los usuarios de Discover de manera diferente a su sitio principal, piense en cómo los vincularía de manera efectiva. Tal vez utilice una sección emergente “Creemos que le gustará lo siguiente” basada en la profundidad de desplazamiento del usuario.
- Consiga que el tráfico se convierta. Si bien Discover es un feed personalizado, el desplazamiento estándar no es muy atractivo. Por lo tanto, concéntrese en conversiones más fáciles, como registros (si es una empresa que primero se suscribe) o ingresos por publicidad, etc.
- Mantenga un registro de sus mejores artistas. El contenido imperecedero se puede actualizar y volver a publicar año tras año. Todavía puede generar valor.
*Lo que quiero decir aquí es que si se prevé que su contenido generará tres acciones y dos enlaces, si lo comparte en las redes sociales y en boletines informativos y generará siete acciones y nueve enlaces, es más probable que se vuelva viral.
Como tal, el algoritmo lo identifica como “digno de descubrir”.
Más recursos:
Esto se publicó originalmente en Liderazgo en SEO.
Imagen de portada: Roman Samborskyi/Shutterstock
(etiquetasToTranslate)SEO

{kind=link}