

Es probable que su sitio sufra de al menos cierta canibalización de contenido, y es posible que ni siquiera se dé cuenta.
La canibalización perjudica el tráfico y los ingresos orgánicos: el impacto puede extenderse desde páginas clave que no se clasifican hasta problemas de algoritmo debido a la baja calidad del dominio.
Sin embargo, la canibalización es difícil de detectar, puede cambiar con el tiempo y existe en un espectro.
Es el “microplástico de SEO”.
En este memo, te mostraré:
- Cómo identificar y arreglar la canibalización de contenido de manera confiable.
- Cómo automatizar la detección de canibalización de contenido.
- Un flujo de trabajo automatizado que puede probar ahora mismo: el detector de canibalización, mi nueva herramienta de canibalización de palabras clave.
Nunca podría haber hecho esto sin Nicole Guercia de AirOps. He diseñado el concepto y probado el estrés del flujo de trabajo automatizado, pero Nicole construyó todo.
Cómo pensar en la canibalización del contenido de la manera correcta
Antes de saltar al flujo de trabajo, debemos aclarar algunos principios rectores sobre la canibalización de contenido que a menudo se malinterpretan.
El mayor error sobre la canibalización es que sucede en el nivel de palabras clave.
En realidad está sucediendo en el nivel de intención del usuario.
Todos debemos dejar de pensar en este concepto como canibalización de palabras clave y en su lugar como canibalización de contenido basada en la intención del usuario.
Con esto en mente, la canibalización …
- Es un objetivo en movimiento: Cuando Google actualiza su comprensión de la intención durante una actualización central, de repente dos páginas pueden competir entre sí que anteriormente no lo hicieron.
- Existe en un espectro: Una página puede competir con otra página o varias páginas, con una superposición de intención del 10% al 100%. Es difícil decir exactamente cuánta superposición está bien sin mirar los resultados y el contexto.
- No se detiene en las clasificaciones: Buscar dos páginas que obtengan una cantidad “sustancial” de impresiones o clasificaciones para las mismas palabras clave (s) pueden ayudarlo a detectar la canibalización, pero no es un método muy preciso. No es suficiente prueba.
- Necesita chequeos regulares: Debe consultar su sitio para la canibalización regularmente y tratar su biblioteca de contenido como un ecosistema “vivo”.
- Puede ser astuto: Muchos casos no están claros. Por ejemplo, la canibalización de contenido internacional no es obvia. A /EN Directory para abordar todos los países de habla inglesa puede competir con el directorio A /EN-US para el mercado estadounidense.
Los diferentes tipos de sitios tienen debilidades fundamentalmente diferentes para la canibalización.
Mi modelo para los tipos de sitios es el modelo integrador vs. agregador. Los minoristas en línea y otros mercados enfrentan casos fundamentalmente diferentes de canibalización que las empresas SaaS o D2C.
Integradores Canibalize entre páginas. Agregadores canibalizar entre los tipos de página.
- Con agregadoresla canibalización a menudo ocurre cuando dos tipos de páginas son demasiado similares. Por ejemplo, puede tener dos tipos de páginas que podrían o no competir entre sí: “Puntos de interés en {City}” y “cosas que hacer en {City}”.
- Con integradoresla canibalización a menudo ocurre cuando las empresas publican contenido nuevo sin mantenimiento y un plan para el contenido existente. Una gran parte del problema es que se vuelve más difícil mantener una descripción general de lo que tiene y a qué palabras/intenciones se dirige a un cierto número de artículos (encontré que la pieza clave es de alrededor de 250 artículos).
Cómo detectar la canibalización de contenido
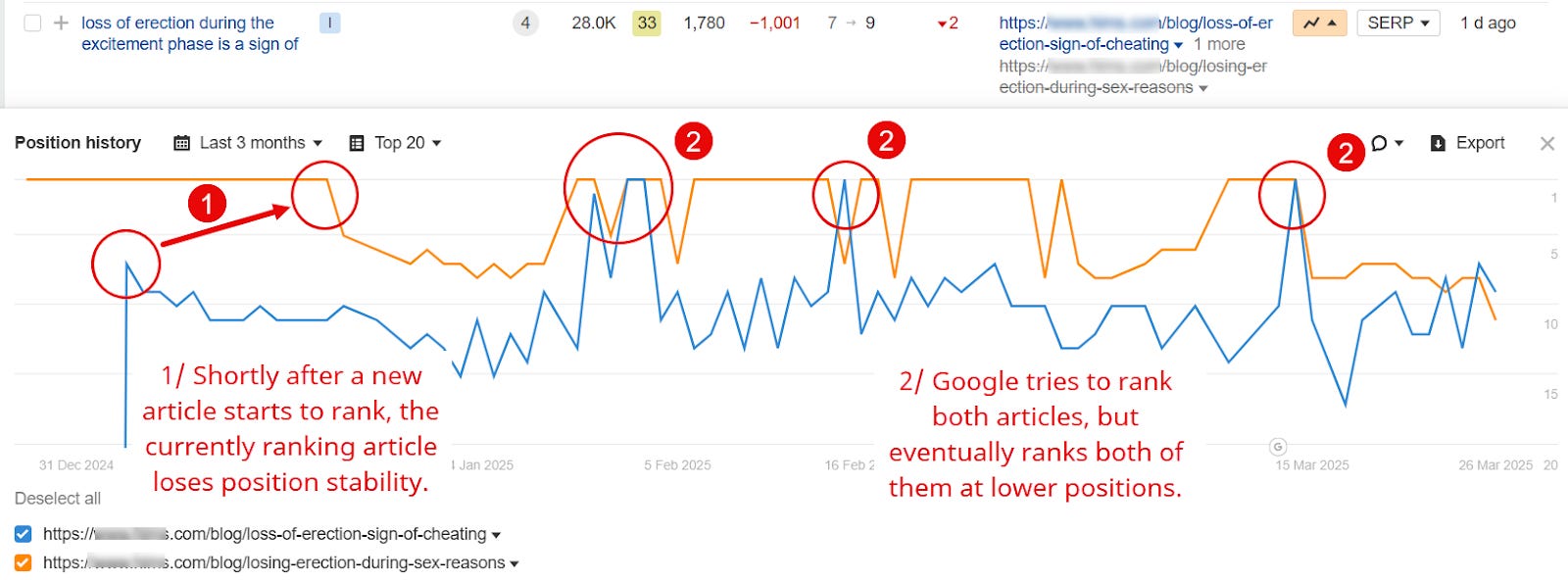 Un ejemplo de canibalización de contenido (crédito de imagen: Kevin Indig)
Un ejemplo de canibalización de contenido (crédito de imagen: Kevin Indig)La canibalización de contenido puede tener uno o más de los siguientes síntomas:
- “URL Flickering”: lo que significa que al menos dos URL se alternan en la clasificación para una o más palabras clave.
- Una página pierde tráfico y/o posiciones de clasificación después de que otra se pone en marcha.
- Una nueva página llega a una meseta de clasificación para su palabra clave principal y no puede entrar en las 3 posiciones principales.
- Google no indexa una nueva página o páginas dentro del mismo tipo de página.
- Los títulos duplicados exactos aparecen en el índice de búsqueda de Google.
- Google informa “rastreado, no indexado” o “descubierto, no indexado” para URL que no tienen contenido delgado o problemas técnicos.
Dado que Google no nos da una señal clara para la canibalización, la mejor manera de medir la similitud entre dos o más páginas es la similitud cosena entre sus incrustaciones tokenizadas (lo sé, es un bocado).
Pero esto es lo que significa: básicamente, compara cuán similares son las dos páginas convirtiendo su texto en números y viendo cuán de cerca apuntan esos números en la misma dirección.
Piénselo como una receta de galletas de chocolate:
- Tokenización = Desglose cada receta (por ejemplo, contenido de página) en ingredientes: harina, azúcar, chips de chocolate, etc.
- Incrustaciones = Convierta cada ingrediente en números, como cuánto de cada ingrediente se usa y cuán importante es cada uno para la identidad de la receta.
- Similitud de coseno = Compare las recetas matemáticamente. Esto le brinda un número entre 0 y 1. Una puntuación de 1 significa que las recetas son idénticas, mientras que 0 significa que son completamente diferentes.
Siga este proceso para escanear su sitio y encontrar candidatos de canibalización:
- Gatear: Raspe su sitio con una herramienta como Screaming Frog (opcionalmente, excluya páginas que no tienen un propósito de SEO) para extraer la URL y el meta título de cada página
- Tokenización: Convierta las palabras tanto en la URL como en el título en piezas de palabras con las que son más fáciles de trabajar. Estas son tus tokens.
- Incrustaciones: Convierta las fichas en números para hacer “Matemáticas de palabras”.
- Semejanza: Calcule la similitud coseno entre todas las URL y meta títulos
Idealmente, esto le da una lista de URL y títulos que son demasiado similares.
En el siguiente paso, puede aplicar el siguiente proceso para asegurarse de que realmente se canibalicen entre sí:
- Extraer contenido: Aislar claramente el contenido principal (excluir la navegación, el pie de página, los anuncios, etc.). Tal vez limpie ciertos elementos, como las palabras de detención.
- Fragmentación o tokenización: Dividir el contenido en trozos significativos (oraciones o párrafos) o tokenizar directamente. Prefiero lo último.
- Incrustaciones: Incrustar los tokens.
- Entidades: Extracto con nombre de entidades de los tokens y pesarse más alto en incrustaciones. En esencia, verificas qué integridades son “cosas conocidas” y les das más poder en tu análisis.
- Agregación de incrustaciones: Incrustos agregados de token/fragmento con un promedio ponderado (p. Ej., TF-IDF) o agrupación ponderada en atención.
- Coseno de similitud: Calcule la similitud coseno entre los incrustaciones resultantes.
Puedes usar el script de mi aplicación si quieres probarlo en las hojas de Google (pero tengo una mejor alternativa para ti en un momento).
Acerca de la similitud de coseno: No es perfecto, pero lo suficientemente bueno.
Sí, puede ajustar los modelos de incrustación para temas específicos.
Y sí, puede usar modelos de incrustación avanzados como transformadores de oraciones en la parte superior, pero este proceso simplificado suele ser suficiente. No es necesario hacer un proyecto de astrofísica.
Cómo arreglar la canibalización
Una vez que haya identificado la canibalización, debe tomar medidas.
Pero no olvide ajustar su enfoque a largo plazo para la creación y gobernanza de contenido. Si no lo hace, todo este trabajo para encontrar y arreglar la canibalización será un desperdicio.
Resolver la canibalización a corto plazo
La acción a corto plazo que debe tomar depende del grado de canibalización y qué tan rápido puede actuar.
“Grado” significa cuán similar es el contenido en dos o más páginas, expresado en la similitud de coseno o contenido.
Aunque no es una ciencia exacta, en mi experiencia, una similitud coseno superior a 0.7 se clasifica como “alta”, mientras que es “bajo” por debajo de un valor de 0.5.
 4 formas de arreglar la canibalización (Crédito de la imagen: Kevin Indig)
4 formas de arreglar la canibalización (Crédito de la imagen: Kevin Indig)Qué hacer si las páginas tienen un alto grado de similitud:
- Canonicalizar o noindex La página cuando ocurre la canibalización debido a problemas técnicos como las URL de parámetros, o si la página de canibalización es irrelevante para SEO, como las páginas de destino pagas. En este caso, Canonicalize la URL de parámetros a la URL no paramétrica (o noindex la página de inicio pagada).
- Consolidar con otra página cuando no es un problema técnico. La consolidación significa combinar el contenido y redirigir las URL. Sugiero tomar la página anterior y/o la página de peor rendimiento y redireccionarse a una nueva y mejor página. Luego, transfiera cualquier contenido útil a la nueva variante.
Qué hacer si las páginas tienen un bajo grado de similitud:
- Noindex o eliminar (Código de estado: 410) Cuando no tiene la capacidad o la capacidad de hacer cambios de contenido.
- Desambiguar El enfoque de la intención del contenido si tiene la capacidad, y si la superposición no es demasiado fuerte. En esencia, desea diferenciar las partes de las páginas que son demasiado similares.
Resolver la canibalización a largo plazo
Es fundamental tomar medidas a largo plazo para ajustar su estrategia o proceso de producción porque la canibalización del contenido es un síntoma de un problema mayor, no una causa raíz.
(A menos que estemos hablando de que Google cambia su comprensión de la intención durante una actualización de algoritmo central, y eso no tiene nada que ver con usted o su equipo).
Los cambios más críticos a largo plazo que debe hacer son:
- Crea una hoja de ruta de contenido: Los integradores de SEO deben mantener una hoja de cálculo viva o una base de datos con todas las URL relevantes para SEO y sus principales palabras clave objetivo y su intención de ajustar la supervisión editorial. Quien esté a cargo de la hoja de ruta de contenido debe asegurarse de que no haya superposición entre artículos y otros tipos de páginas. Los escritores deben tener una intención de objetivo clara para contenido nuevo y existente.
- Desarrollar una arquitectura de sitio clara: El colgante de un mapa de contenido para agregadores de SEO es un mapa de arquitectura del sitio, que es simplemente una descripción general de los diferentes tipos de páginas y la intención que se dirigen. Es fundamental subrayar la intención al definirlo con palabras clave de ejemplo que verifica de forma regular (“¿Todavía estamos clasificando bien para esas palabras clave?”) Para que coincida con la comprensión y los competidores de Google.
La última pregunta es: “¿Cómo sé cuándo se soluciona la canibalización del contenido?”
La respuesta es cuando desaparecen los síntomas mencionados en el capítulo anterior:
- Los problemas de indexación resuelven.
- El parpadeo de URL desaparece.
- No aparecen títulos duplicados en el índice de búsqueda de Google.
- Los problemas “rastreados, no indexados” o “descubiertos, no indexados” disminuyen.
- Las clasificaciones estabilizan y rompen una meseta (si la página no tiene otros problemas aparentes).
Y, después de trabajar con mis clientes en este marco manual durante años, decidí que es hora de automatizarlo.
Introducción: un detector de canibalización totalmente automatizado
Junto con Nicole, utilicé AirOps para construir un flujo de trabajo de IA totalmente automatizado que pasa por 37 pasos para detectar la canibalización en cuestión de minutos.
Realiza un análisis exhaustivo de la canibalización de contenido al examinar las clasificaciones de palabras clave, la similitud de contenido y los datos históricos.
A continuación, desglosaré los pasos más importantes que automatiza en su nombre:
1. Procesamiento de URL inicial
El flujo de trabajo extrae y normaliza el dominio y el nombre de la marca de la URL de entrada.
Este paso fundamental establece la identidad del sitio web objetivo y crea la línea de base para todos los análisis posteriores.
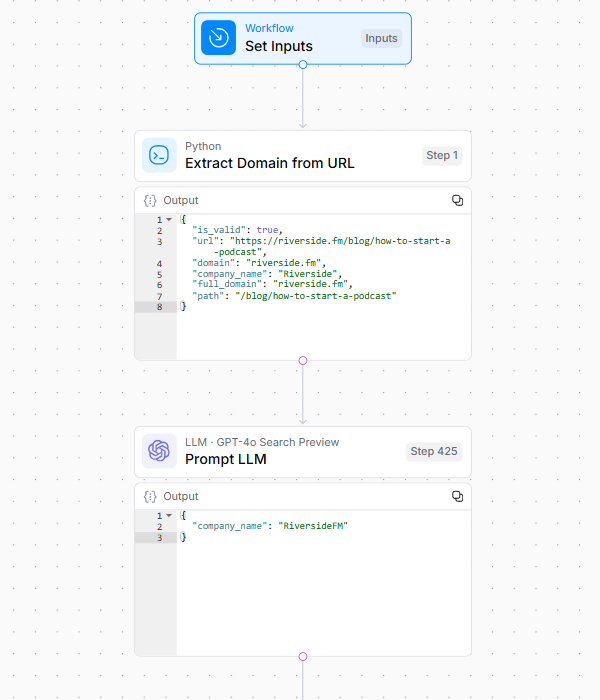 Crédito de la imagen: Kevin Indig
Crédito de la imagen: Kevin Indig2. Análisis de contenido objetivo
Para garantizar que el sistema tenga material fuente de calidad para analizar y comparar con los competidores, el paso 2 implica:
- Raspando la página.
- Validando y analizar la estructura HTML para la extracción de contenido principal.
- Limpiar el contenido del artículo y generar integridades objetivo.
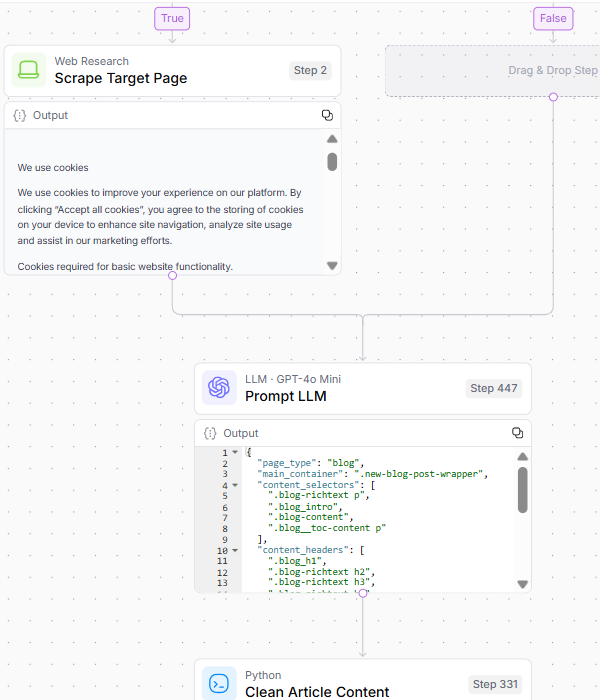 Crédito de la imagen: Kevin Indig
Crédito de la imagen: Kevin Indig3. Análisis de palabras clave
El paso 3 revela la visibilidad de búsqueda de la URL objetivo y las posibles vulnerabilidades por:
- Análisis de palabras clave de clasificación a través de datos SEMRUSH.
- Filtrado de términos de marca versus no marca.
- Identificar la superposición de SERP con URL en competencia.
- Realización de análisis de clasificación histórica.
- Determinar el valor de la página basado en múltiples métricas.
- Analizar cambios diferenciales de posición con el tiempo.
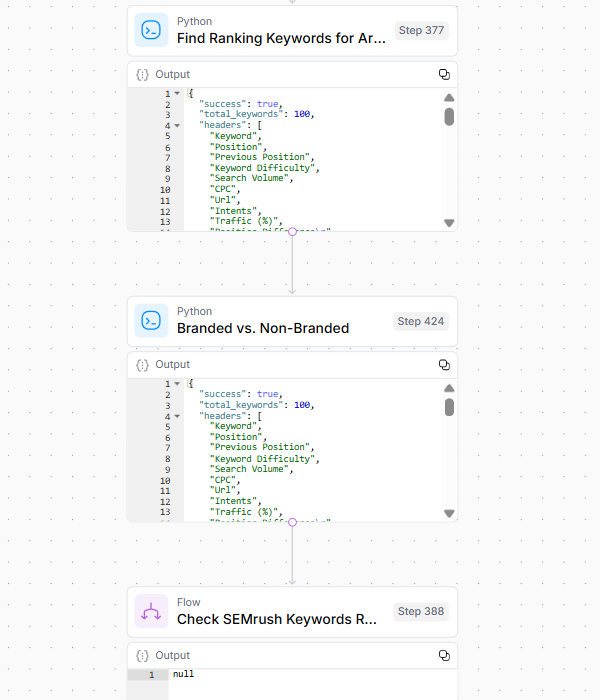 Crédito de la imagen: Kevin Indig
Crédito de la imagen: Kevin Indig4. Análisis de contenido competitivo (iteración sobre URL de la competencia)
El paso 4 recopila un contexto adicional para la canibalización procesando iterativamente cada URL competitiva en los resultados de búsqueda a través de los pasos anteriores.
 Crédito de la imagen: Kevin Indig
Crédito de la imagen: Kevin Indig5. Generación final de informes
En el paso final, el flujo de trabajo limpia los datos y genera un informe procesable.
 Crédito de la imagen: Kevin Indig
Crédito de la imagen: Kevin IndigPruebe el detector de canibalización de contenido automatizado
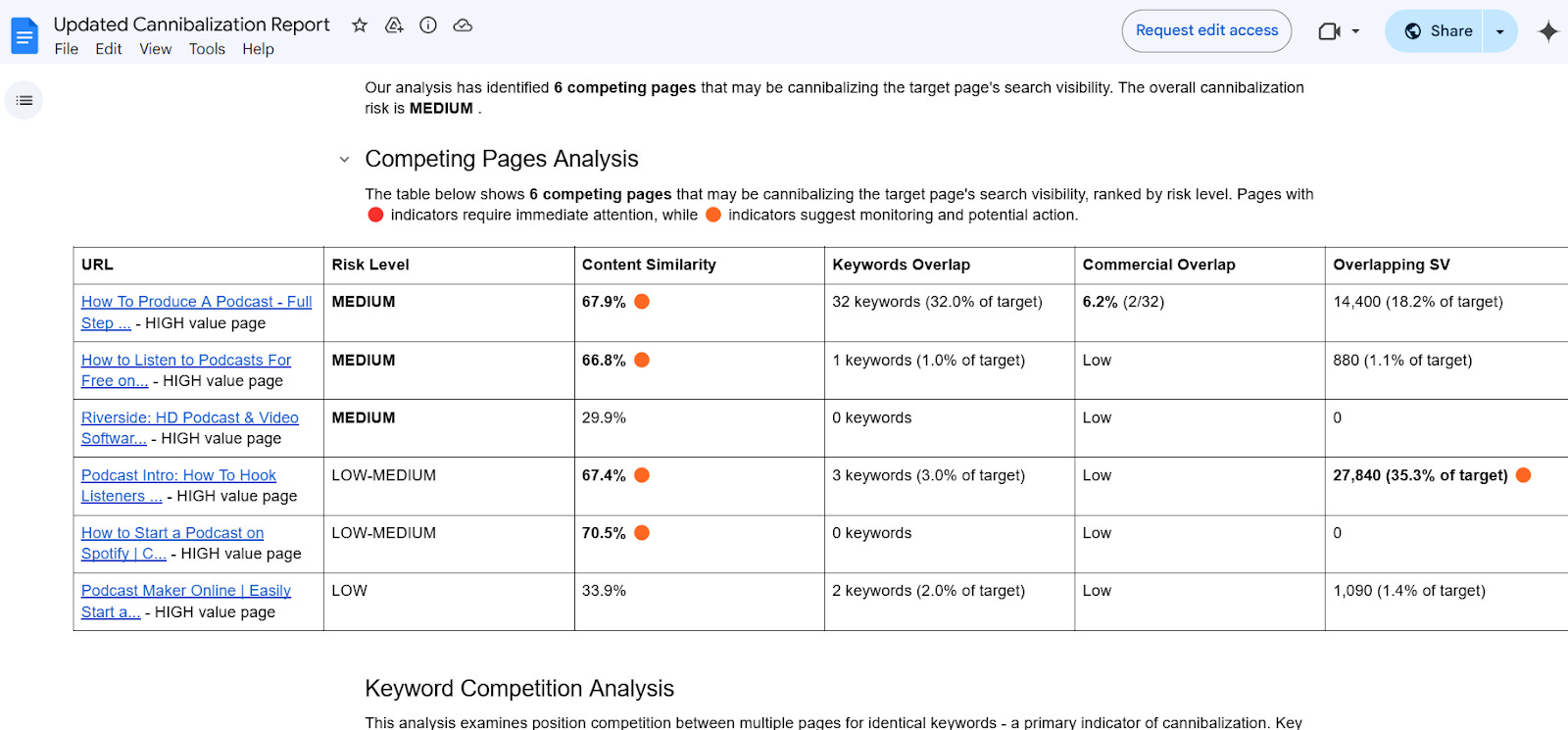 Crédito de la imagen: Kevin Indig
Crédito de la imagen: Kevin IndigPruebe el detector de canibalización y consulte un informe de ejemplo.
Algunas cosas a tener en cuenta:
- Esta es una versión temprana. Estamos planeando optimizarlo y mejorarlo con el tiempo.
- El flujo de trabajo puede salir de tiempo debido a una gran cantidad de solicitudes. Intencionalmente limitamos el uso para no sentirnos abrumados por las llamadas de API (cuestan dinero). Monitorearemos el uso y podríamos elevar temporalmente el límite, lo que significa que si su primer intento no es exitoso, intente nuevamente en unos minutos. Podría ser un aumento temporal en el uso.
- Soy asesor de AirOps pero no fue pagado ni incentivado de ninguna otra manera para construir este flujo de trabajo.
Deje sus comentarios en los comentarios.
¡Nos encantaría saber cómo podemos llevar el detector de canibalización al siguiente nivel!
Aumente sus habilidades con las ideas de expertos semanales de Growth Memo. ¡Suscríbete gratis!
Imagen Feaded: Paulo Bobita/Search Engine Journal
(tagstotranslate) AI generativo

{kind=link}